Yongsen Mao
I will be a Ph.D. student at HKUST in the Intelligent Graphics Lab, starting February 2026, supervised by Prof. Yuan Liu. I received my thesis-based M.Sc. from Simon Fraser University(SFU), supervised by Prof. Manolis Savva and mentored by Prof. Angel Xuan Chang in the GrUVi Lab. I earned my B.Eng. from Zhejiang University(ZJU) and SFU. I also worked as a full-time Research Engineer at ManycoreTech. My primary research interests lie in the generation and understanding of 3D scenes for downstream vision and robotics applications.
sammaoys-{at}-outlook-[dot]-com
Google Scholar
GitHub
News
2025/09 Our paper SpatialLM is accepted to NeurIPS 2025.
2025/06 We released SpatialLM 1.1, an improved version of SpatialLM.
2025/03 We started a new open-source project: SpatialLM.
2024/06 Our layout controlnet model released on huggingface kujiale-ai/controlnet-layout.
2024/05 Our papers HSSD-200 and Ego-Exo4D are accepted to CVPR 2024.
Publications

SpatialLM: Training Large Language Models for Structured Indoor Modeling
SpatialLM is a large language model designed to process 3D point cloud data and generate structured 3D scene understanding outputs. These outputs include architectural elements like walls, doors, windows, and oriented object boxes with their semantic categories. Unlike previous methods which exploit task-specific network designs, our model adheres to the standard multimodal LLM architecture and is fine-tuned directly from open-source LLMs. To train SpatialLM, we collect a large-scale, high-quality synthetic dataset consisting of the point clouds of 12,328 indoor scenes (54,778 rooms) with ground-truth 3D annotations, and conduct a careful study on various modeling and training decisions. On public benchmarks, our model gives state-of-the-art performance in layout estimation and competitive results in 3D object detection. With that, we show a feasible path for enhancing the spatial understanding capabilities of modern LLMs for applications in augmented reality, embodied robotics, and more.
NeurIPS 2025
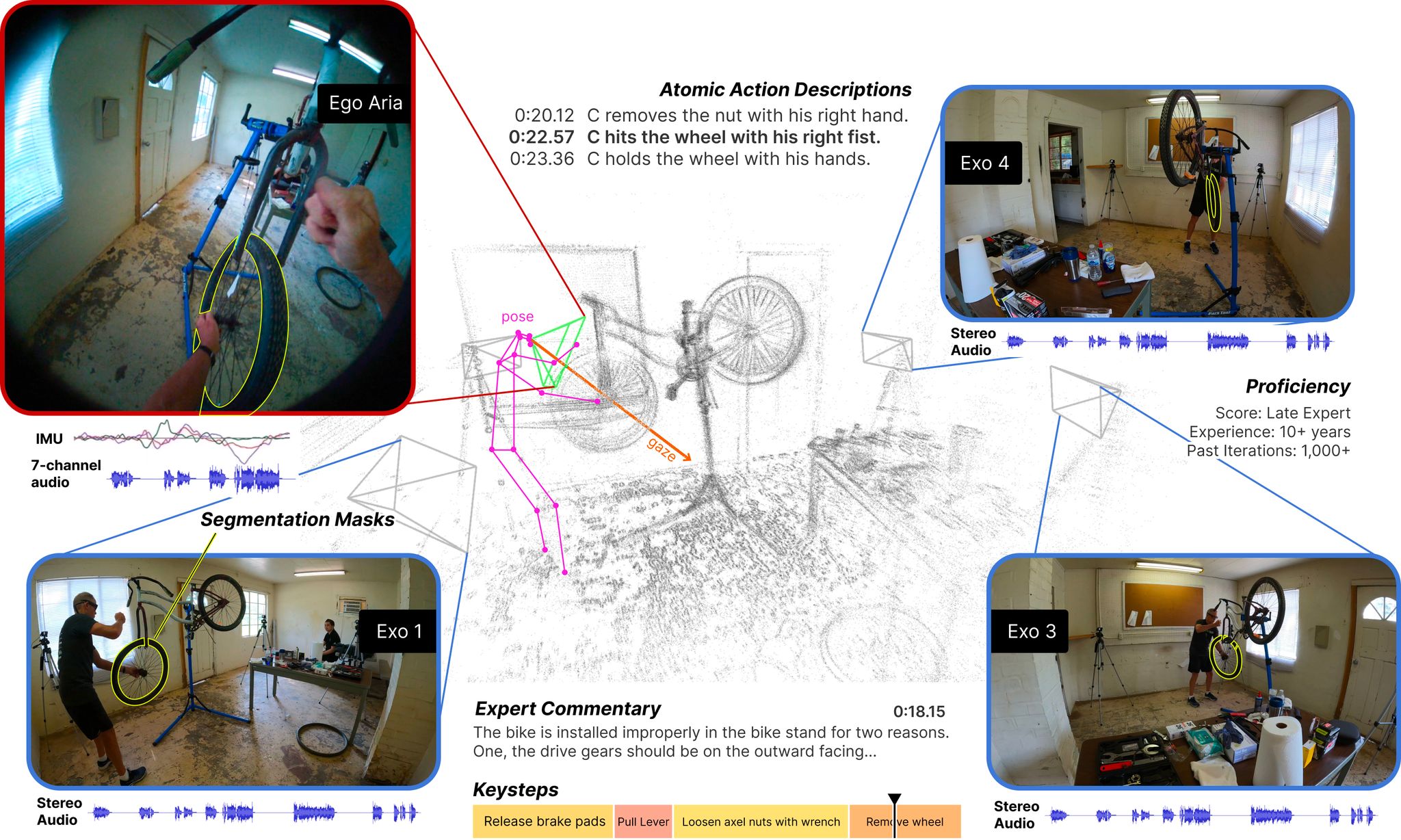
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, Eugene Byrne, Zach Chavis, Joya Chen, Feng Cheng, Fu-Jen Chu, Sean Crane, Avijit Dasgupta, Jing Dong, Maria Escobar, Cristhian Forigua, Abrham Gebreselasie, Sanjay Haresh, Jing Huang, Md Mohaiminul Islam, Suyog Jain, Rawal Khirodkar, Devansh Kukreja, Kevin J Liang, Jia-Wei Liu, Sagnik Majumder, Yongsen Mao , Miguel Martin, Effrosyni Mavroudi, Tushar Nagarajan, Francesco Ragusa, Santhosh Kumar Ramakrishnan, Luigi Seminara, Arjun Somayazulu, Yale Song, Shan Su, Zihui Xue, Edward Zhang, Jinxu Zhang, Angela Castillo, Changan Chen, Xinzhu Fu, Ryosuke Furuta, Cristina Gonzalez, Prince Gupta, Jiabo Hu, Yifei Huang, Yiming Huang, Weslie Khoo, Anush Kumar, Robert Kuo, Sach Lakhavani, Miao Liu, Mi Luo, Zhengyi Luo, Brighid Meredith, Austin Miller, Oluwatumininu Oguntola, Xiaqing Pan, Penny Peng, Shraman Pramanick, Merey Ramazanova, Fiona Ryan, Wei Shan, Kiran Somasundaram, Chenan Song, Audrey Southerland, Masatoshi Tateno, Huiyu Wang, Yuchen Wang, Takuma Yagi, Mingfei Yan, Xitong Yang, Zecheng Yu, Shengxin Cindy Zha, Chen Zhao, Ziwei Zhao, Zhifan Zhu, Jeff Zhuo, Pablo Arbelaez, Gedas Bertasius, David Crandall, Dima Damen, Jakob Engel, Giovanni Maria Farinella, Antonino Furnari, Bernard Ghanem, Judy Hoffman, C. V. Jawahar, Richard Newcombe, Hyun Soo Park, James M. Rehg, Yoichi Sato, Manolis Savva, Jianbo Shi, Mike Zheng Shou, Michael Wray
We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). 740 participants from 13 cities worldwide performed these activities in 123 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,286 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources are open sourced to fuel new research in the community.
CVPR 2024, Oral

Habitat Synthetic Scenes Dataset (HSSD-200):
An Analysis of 3D Scene Scale and Realism Tradeoffs for ObjectGoal Navigation
Mukul Khanna*, Yongsen Mao*, Hanxiao Jiang, Sanjay Haresh, Brennan Shacklett, Dhruv Batra, Alexander Clegg, Eric Undersander, Angel X. Chang, Manolis Savva
We contribute the Habitat Synthetic Scenes Dataset (HSSD-200), a dataset of 211 high-quality 3D scenes, and use it to test navigation agent generalization to realistic 3D environments. Our dataset represents real interiors and contains a diverse set of 18,656 models of real-world objects. We investigate the impact of synthetic 3D scene dataset scale and realism on the task of training embodied agents to find and navigate to objects (ObjectGoal navigation). By comparing to synthetic 3D scene datasets from prior work, we find that scale helps in generalization, but the benefits quickly saturate, making visual fidelity and correlation to real-world scenes more important. Our experiments show that agents trained on our smaller-scale dataset can match or outperform agents trained on much larger datasets. Surprisingly, we observe that agents trained on just 122 scenes from our dataset outperform agents trained on 10,000 scenes from the ProcTHOR-10K dataset in terms of zero-shot generalization in real-world scanned environments.
CVPR 2024

MultiScan: Scalable RGBD scanning for 3D environments with articulated objects
We introduce MultiScan, a scalable RGBD dataset construction pipeline leveraging commodity mobile devices to scan indoor scenes with articulated objects and web-based semantic annotation interfaces to efficiently annotate object and part semantics and part mobility parameters. We use this pipeline to collect 230 scans of 108 indoor scenes containing 9458 objects and 4331 parts. The resulting MultiScan dataset provides RGBD streams with per-frame camera poses, textured 3D surface meshes, richly annotated part-level and object-level semantic labels, and part mobility parameters. We validate our dataset on instance segmentation and part mobility estimation tasks and benchmark methods for these tasks from prior work. Our experiments show that part segmentation and mobility estimation in real 3D scenes remain challenging despite recent progress in 3D object segmentation.
NeurIPS 2022
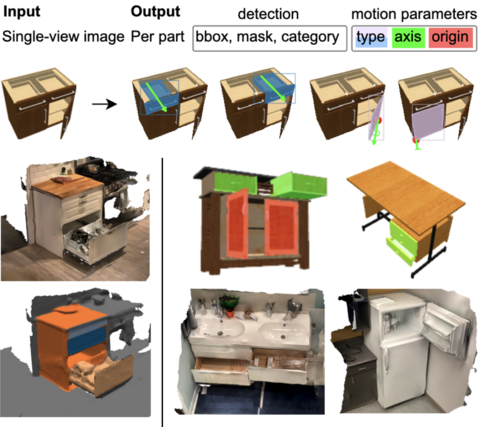
OPD: Single-view 3D Openable Part Detection
We address the task of predicting what parts of an object can open and how they move when they do so. The input is a single image of an object, and as output we detect what parts of the object can open, and the motion parameters describing the articulation of each openable part. To tackle this task, we create two datasets of 3D objects: OPDSynth based on existing synthetic objects, and OPDReal based on RGBD reconstructions of real objects. We then design OPDRCNN, a neural architecture that detects openable parts and predicts their motion parameters. Our experiments show that this is a challenging task especially when considering generalization across object categories, and the limited amount of information in a single image. Our architecture outperforms baselines and prior work especially for RGB image inputs.
ECCV 2022, Oral